Self-Supervised Goal-Reaching Results in Multi-Agent Cooperation and Exploration

What is this research about?
The Problem: Training multiple reinforcement learning agents to work together is hard, especially since usually it requires carefully designing a task-specific reward function that encourages agents to cooperate effectively.
Our Solution: We reframe this problem instead as a goal-reaching problem: we give the agents a shared goal and let them figure out how to cooperate and reach that goal without any additional guidance. The agents do this by learning how to maximize the likelihood of visiting this shared goal. Despite giving very little guidance to the agents, we observe that our method performs very well on a variety of tasks, outperforming other methods with access to the same signal. We also observe the agents exploring different strategies, despite never explicitly incentivizing this exploration.
Abstract
For groups of autonomous agents to achieve a particular goal, they must engage in coordination, long-horizon reasoning, and credit assignment to determine which action by which agents contributed to success. While such tasks are usually viewed as scalar reward maximization problems in a multi-agent RL setting, we reframe this problem as a multi-agent goal-conditioned RL problem where agents cooperate to maximize the likelihood of visiting a certain goal. This problem setting enables human users to specify tasks via a single goal state, rather than implementing a complex reward function. While the feedback signal is quite sparse, we will demonstrate how reframing this as a goal-conditioned problem allows us to leverage self-supervised goal-reaching techniques to learn such problems. On MARL benchmarks, our proposed method outperforms alternative approaches that have access to the same sparse reward signal as our method. Intriguingly, while our method has no explicit mechanism for exploration, our empirical results demonstrate the same “emergent exploration” phenomenon observed in self-supervised goal-reaching algorithms in the single-agent setting, including in settings where alternative approaches never witness a successful trial.
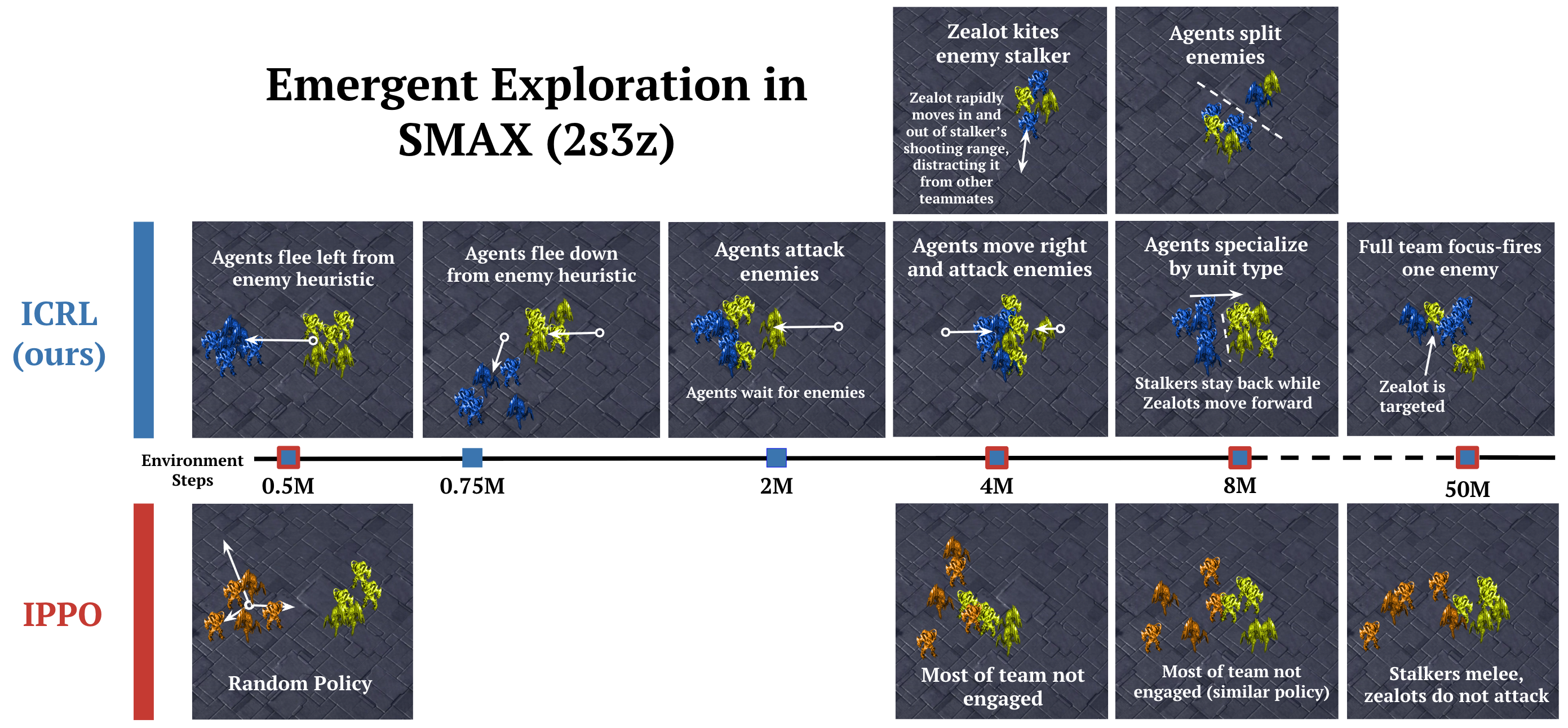
How does ICRL learn to play StarCraft? We visualize the exploration strategies of (Top Row) ICRL (our method) and (Bottom Row) IPPO on the SMAX (2s3z) environment over 50 million training environment steps. We observe that the ICRL algorithm learns more complex behaviors.
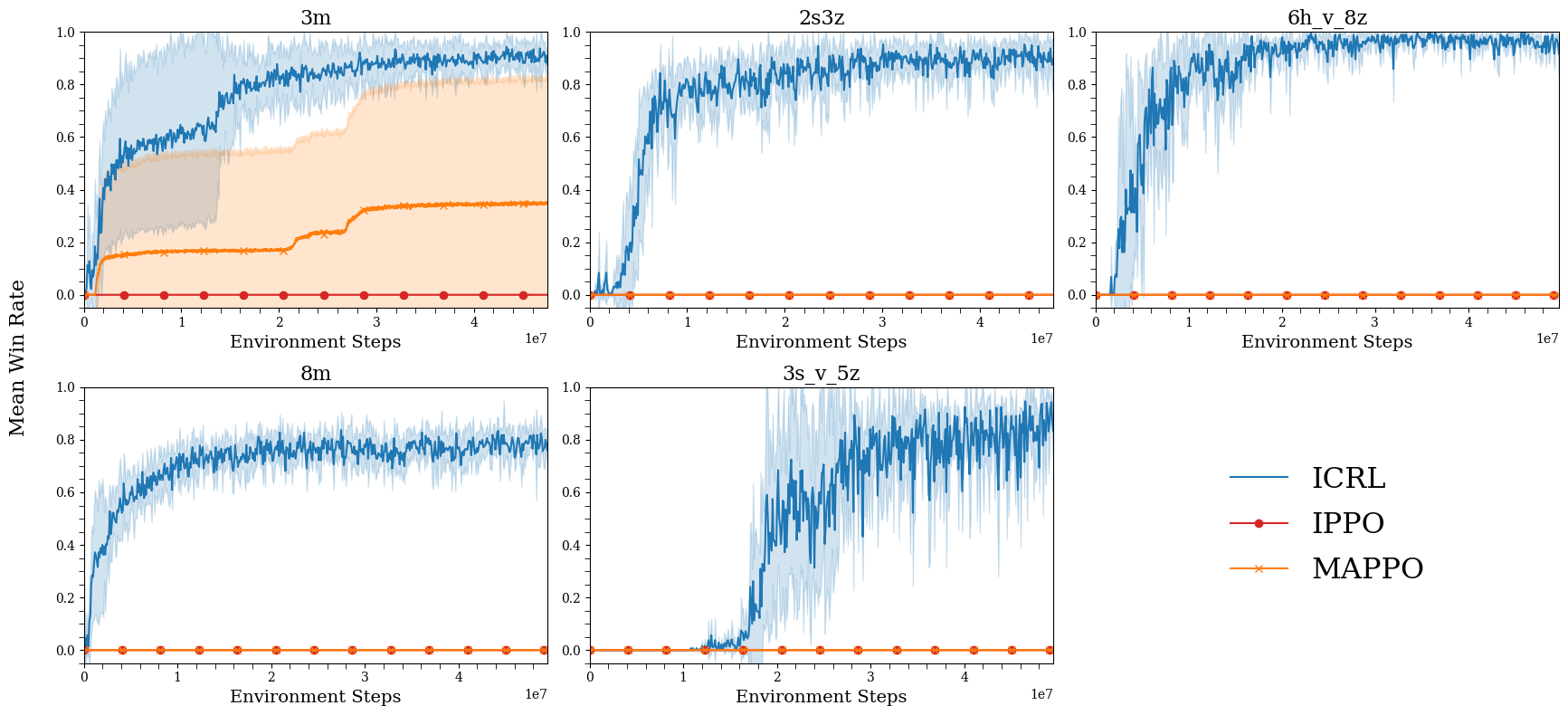
Efficient learning on the StarCraft Multi-Agent Challenge (SMAX). We compare ICRL (our method) to IPPO and MAPPO on five settings from the SMAX benchmark. On the 3m setting, our method achieves a win rate that is ∼ 3× higher than MAPPO, while the IPPO baseline has a win rate of zero. On the 2s3z, 6h_v_8z, 8m, and 3s_v_5z settings, only our method achieves a non-zero win rate.
Examples of Learned Policies

Citation
@misc{gcmarl2025selfsupervisedgoalreachingmultiagent,
title={Self-Supervised Goal-Reaching Results in Multi-Agent Cooperation and Exploration},
author={Chirayu Nimonkar and Shlok Shah and Catherine Ji and Benjamin Eysenbach},
year={2025},
eprint={2509.10656},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.10656},
}